6分钟阅读时间
【七夕福利】k均值聚类算法告诉你到哪里找对象
用k均值算法进行一个简单的数据分析。
一年一度的中国情人节又到了,广大单身狗们是不是又在发愁自己的终身大事呢?不要慌,今年有机器学习的各种算法来帮大家,我们在这里挑一款比较简单的叫做k 均值聚类的算法给大家做一个示范。
k 均值算法
如果没有接触过机器学习的话,一听这个名字k 均值算法,是不是有一种很高大上的感觉呢?再看看维基百科的介绍,更蒙了:
k-平均算法源于信号处理中的一种向量量化方法,现在则更多地作为一种聚类分析方法流行于数据挖掘领域。k-平均聚类的目的是:把 n 个点(可以是样本的一次观察或一个实例)划分到 k 个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。这个问题将归结为一个把数据空间划分为 Voronoi cells 的问题。
不要慌,跟着我一步一步往下走,最终我们还是只用寥寥几行代码搞定这个看上去很牛逼的东东。
获取数据
做任何算法之前,首先是要获取数据,数据来源很多种,可能是公开数据,可能是产品数据,可能是通过各种渠道收集上来的数据。在这里为了方便起见,我们还是跟上一篇一样,直接从国家统计局的第六次人口普查结果取数据,这一次我们取第《1-8 各地区分性别、受教育程度的 6 岁及以上人口》作为我们的数据来源。同样的,在读入数据之前,你需要简单地对 csv 文件作一下处理,把全国这一行删掉,把几列的名称改一下,然后读入数据:
df = pd.read_csv('chnedu.csv')
为了方便大家操作,我把做好的数据放在 github 上,点此下载。
处理数据
为了计算方便,我们对数据简单处理一下:
df['highedu'] = (df['大学本科小计'] + df['研究生小计']) / df['6岁及以上人口合计']
df['gender'] = df['6岁及以上人口男'] / df['6岁及以上人口女']
假定我们只从两个维度考虑问题,第 1 个维度是受过高等教育的人群占总人口的百分比,第 2 个维度是所有人口中的男女比例,实际上 k 均值算法可以处理很多维度,我们这里简化一下,是为了后面作图方便。
散点图
有了两个维度,一个作 X 轴,一个作 Y 轴,我们就可以开始画图了,是不是有点迫不及待了呢?简单,寥寥数行代码而已:
fig = plt.figure(figsize = (9,7))
ax1 = fig.add_subplot(111)
ax1.scatter(df['gender'], df['highedu'], c = 'r', marker = 'o')
plt.show()
第 1 行定义图片大小,第 2 行添加子图,第 3 行指定要画散点图,X 轴用男女性别比,Y 轴用高等教育比,第 4 行画图:

唔,从图上看,好像是地区之间有点差异,但是我们完全不知道哪个点对应哪个省区,下面我们把省区的名字显示在图上:
for i, txt in enumerate(df['地区']):
ax1.annotate(txt, (df['gender'][i], df['highedu'][i]))

这回明显看出来了,北京、上海、天津受过高等教育的人群比例远高于全国其它省份,从男女比例上来看,天津的男性要远多于女性(是这样吗?请天津的朋友告诉我),而河南是全国所有省份里男女比最接近 1 比 1 的,其它所有地方都是男多女少的局面。北京、上海男性略多于女性,但还没有达到天津这样的差异,天津似乎是个适合大龄女青年找对象的好地方,如果追求高学历的话,北京上海也不错。
但是,不要急,别忘了,我们上面的 X 轴是以全部人口的男女比例做的,那么如果只看高学历人群的男女比例呢?我们把 X 轴的计算公式换一下,其他什么都不变,再来看一下:
df['gender'] = (df['大学本科男'] + df['研究生男']) / (df['大学本科女'] + df['研究生女'])
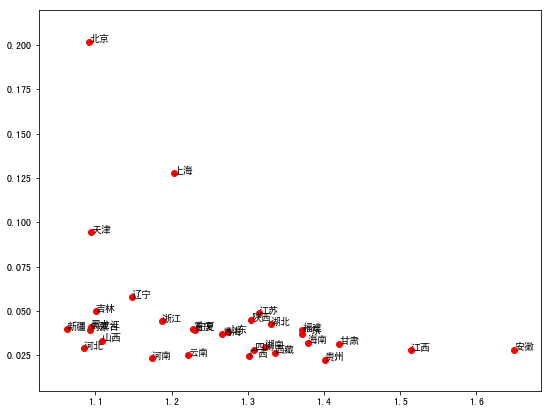
这回数据变得有点不一样了,在所有受过高等教育的人里面,北京女性的受教育程度明显较高,天津也不差,上海则是男性要多于女性。这告诉我们什么呢?如果你是一个大龄女青年,你到上海找到另一半的可能性要高于北京和天津。
k 均值聚类
最后,我们再把所有这些点分一个类,以供全国朋友们参考。这时候就要用到 k 均值聚类算法了,代码也很简单:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 4)
X_clustered = kmeans.fit_predict(df[['gender', 'highedu']])
LABEL_COLOR_MAP = {0:'r', 1:'g', 2:'b', 3:'m'}
label_color = [LABEL_COLOR_MAP[l] for l in X_clustered]
ax1.scatter(df['gender'], df['highedu'], c = label_color, marker = 'o')
第 1 行引入算法,第 2 行创建算法,这里我们指定分成 4 类,当然你也可以指定 3 类或 5 类,第 3 行机器会自动运行算法把数据分开,接下来的 2 行是给分开的类每一类一个不同的颜色,最后我们把点画在图上:
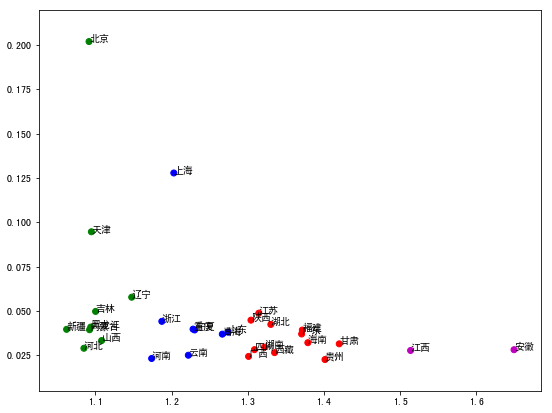
最后的分类结果其实满有意思,我们并没有告诉机器任何事实,而机器根据数据自动把东北、华北和西北(大致)分在了第一集团里面。以上就是 k 均值聚类的用法,主要作用就是机器自动分类,但最终对于分类的解读还是需要由人的大脑来完成,也许在这里的意义是说,如果你要在全国开设婚姻介绍所的话,也许可以根据这样的分类建立分部。同时我们看到,选择不同的座标轴参数对于分类算法的最终结果影响是巨大的,如果你要得到更加真实准确的结果,还应该把人口年龄分布、婚姻状况以及其它更多因素考虑进来,这里只是一个简单的演示,只是想告诉大家使用 Python 进行机器学习有多么的简单。
美化
为了让我们的图形更漂亮一些,我们只需要在代码的最开始处添加 2 行代码:
import seaborn as sns
sns.set()
引入seaborn这个库,它本身是对matplotlib的一个扩充,新增了很多图形,但即使什么都不做,它也能自动让图形比原生的matplotlib漂亮一些:
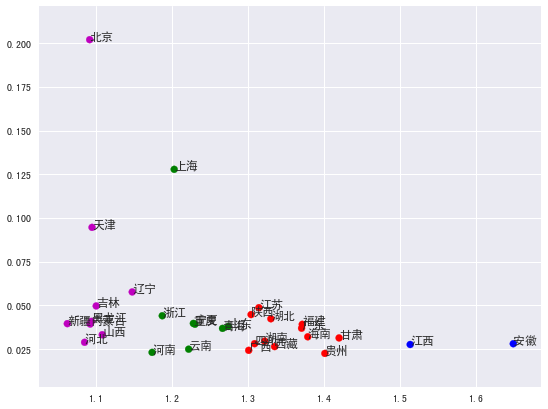
最后,附上完整代码:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans
sns.set()
df = pd.read_csv('chnedu.csv')
df['highedu'] = (df['大学本科小计'] + df['研究生小计']) / df['6岁及以上人口合计']
df['gender'] = (df['大学本科男'] + df['研究生男']) / (df['大学本科女'] + df['研究生女'])
plt.rcParams['font.sans-serif']=['SimHei']
fig = plt.figure(figsize = (9,7))
ax1 = fig.add_subplot(111)
kmeans = KMeans(n_clusters = 5)
X_clustered = kmeans.fit_predict(df[['gender', 'highedu']])
LABEL_COLOR_MAP = {0:'r', 1:'g', 2:'b', 3:'m', 4:'k'}
label_color = [LABEL_COLOR_MAP[l] for l in X_clustered]
ax1.scatter(df['gender'], df['highedu'], c = label_color, marker = 'o')
for i, txt in enumerate(df['地区']):
ax1.annotate(txt, (df['gender'][i], df['highedu'][i]))
plt.show()
交互
用 matplotlib 做的图是静态的,没有交互效果,如果我们希望鼠标移上去时有相应的动作,那么应该怎么做呢?这时候我们可以放弃 matplotlib,而改用 plotly,可以做出既漂亮又有交互效果的图,使用方式也很简单:
import pandas as pd
from sklearn.cluster import KMeans
from plotly.offline import init_notebook_mode, iplot
import plotly.graph_objs as go
init_notebook_mode(connected=True)
df = pd.read_csv('chnedu.csv')
df['highedu'] = (df['大学本科小计'] + df['研究生小计']) / df['6岁及以上人口合计']
df['gender'] = (df['大学本科男'] + df['研究生男']) / (df['大学本科女'] + df['研究生女'])
# Set a 3 KMeans clustering
kmeans = KMeans(n_clusters = 4)
# Compute cluster centers and predict cluster indices
df['cluster'] = kmeans.fit_predict(df[['gender', 'highedu']])
data = []
for i in range(0, 4):
trace = go.Scatter(
x = df.loc[df.cluster==i].gender,
y = df.loc[df.cluster==i].highedu,
text = df.loc[df.cluster==i].地区,
mode = 'markers'
)
data.append(trace)
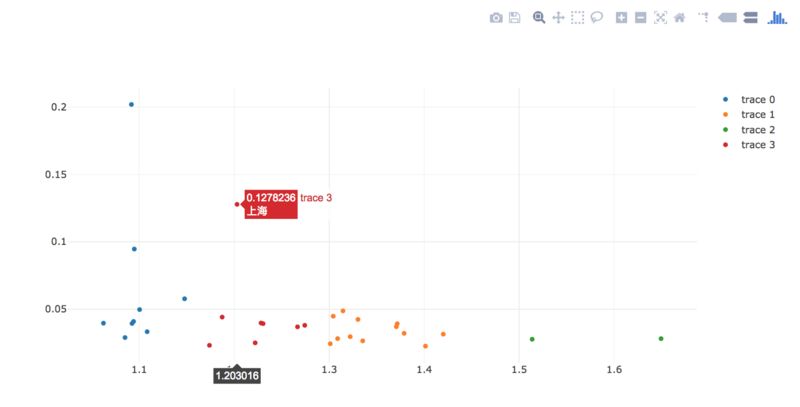
iplot(data, filename='basic-scatter')
做出来的图形却很漂亮并且带有交互效果:
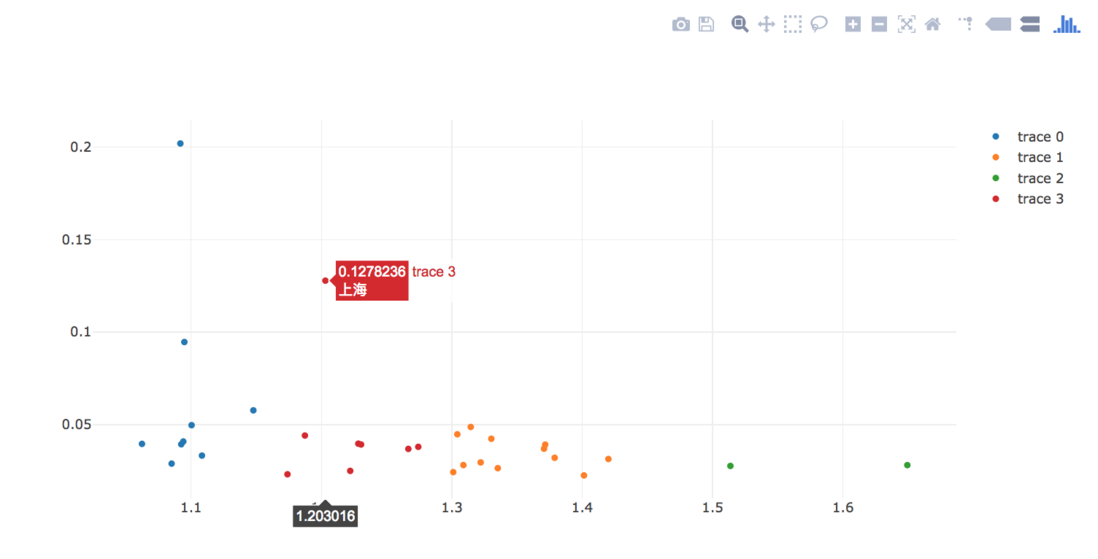
评论